

Network Observability
OpsRamp จาก Hewlett Packard Enterprise คือแพลตฟอร์มบริหารจัดการปฏิบัติการด้านไอที (IT Operations Management) แบบครบวงจร ที่มาพร้อมความสามารถด้าน Network Observability ระดับองค์กร ช่วยให้คุณตรวจสอบและมองเห็นการทำงานของโครงสร้างพื้นฐานเครือข่ายได้อย่างลึกซึ้งแบบเรียลไทม์ เพื่อยกระดับประสิทธิภาพ ความน่าเชื่อถือ และความปลอดภัยของระบบทั้งหมด OpsRamp มอบ Observability ที่ครบกว่าครบครันด้วยความสามารถหลักที่ช่วยให้องค์กรก้าวข้ามความซับซ้อนได้แก่ Network Observability, AI-Power Analytics และ Intelligent Automation
Unified Observability
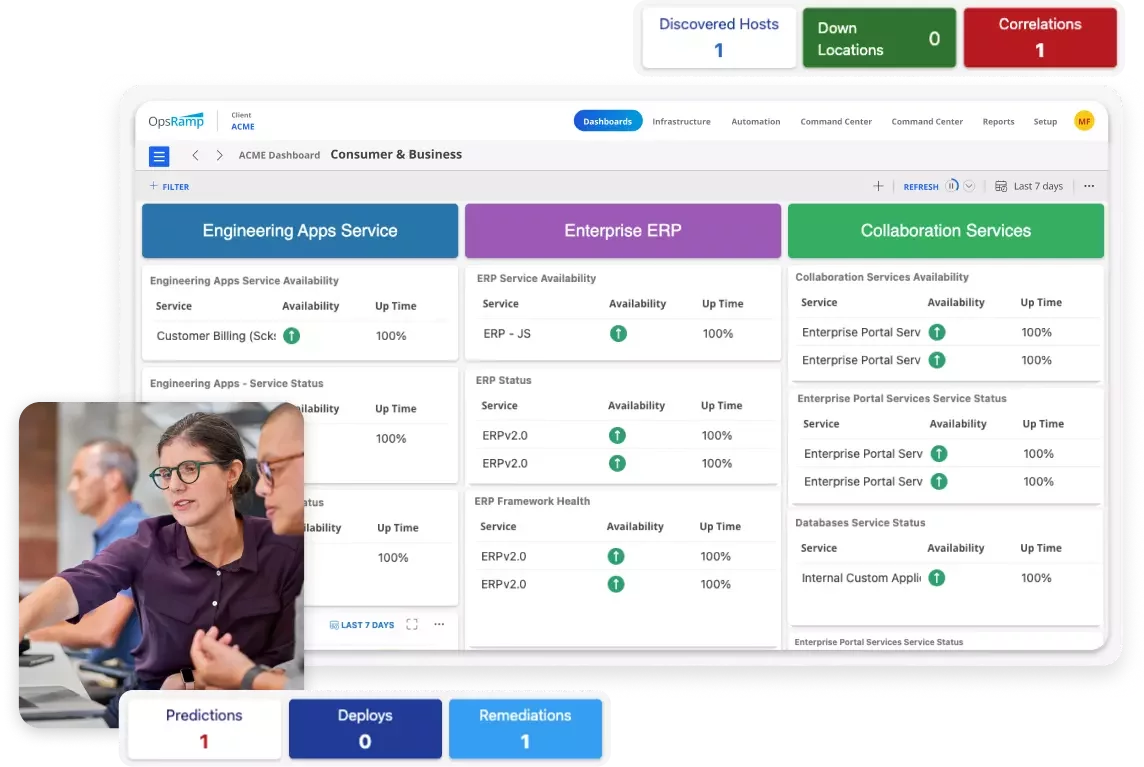
End-to-End Discovery
สภาพแวดล้อมไอทีขององค์กรในปัจจุบันมีความหลากหลายและกระจายตัวมากขึ้น ตั้งแต่ Public และ Private Cloud ไปจนถึง Edge Locations และยังรวมถึงเทคโนโลยีทั้งแบบดั้งเดิมและ Cloud-native อย่าง Kubernetes, Docker, Microservices และ Serverless Architectures ขณะเดียวกัน Workloads ด้าน AIก็ถูกใช้งานข้ามทุกแพลตฟอร์มอย่างต่อเนื่อง ทำให้การมองเห็นระบบแบบครบวงจรกลายเป็นความท้าทายสำคัญ
OpsRamp ช่วยให้คุณก้าวข้ามความซับซ้อนนี้ด้วยความสามารถในการ Discover และ Map ทุก Resource ได้แบบอัตโนมัติ พร้อมการ Monitoring แบบ Native ที่ครอบคลุมทั้ง Infrastructure และ Applications ทีม IT Ops และ DevOps สามารถมองเห็น Health ของ Services และ Performance ของระบบทั้งหมดแบบ Real-time พร้อม Context เชิงลึกตั้งแต่ต้นทางถึงปลายทาง
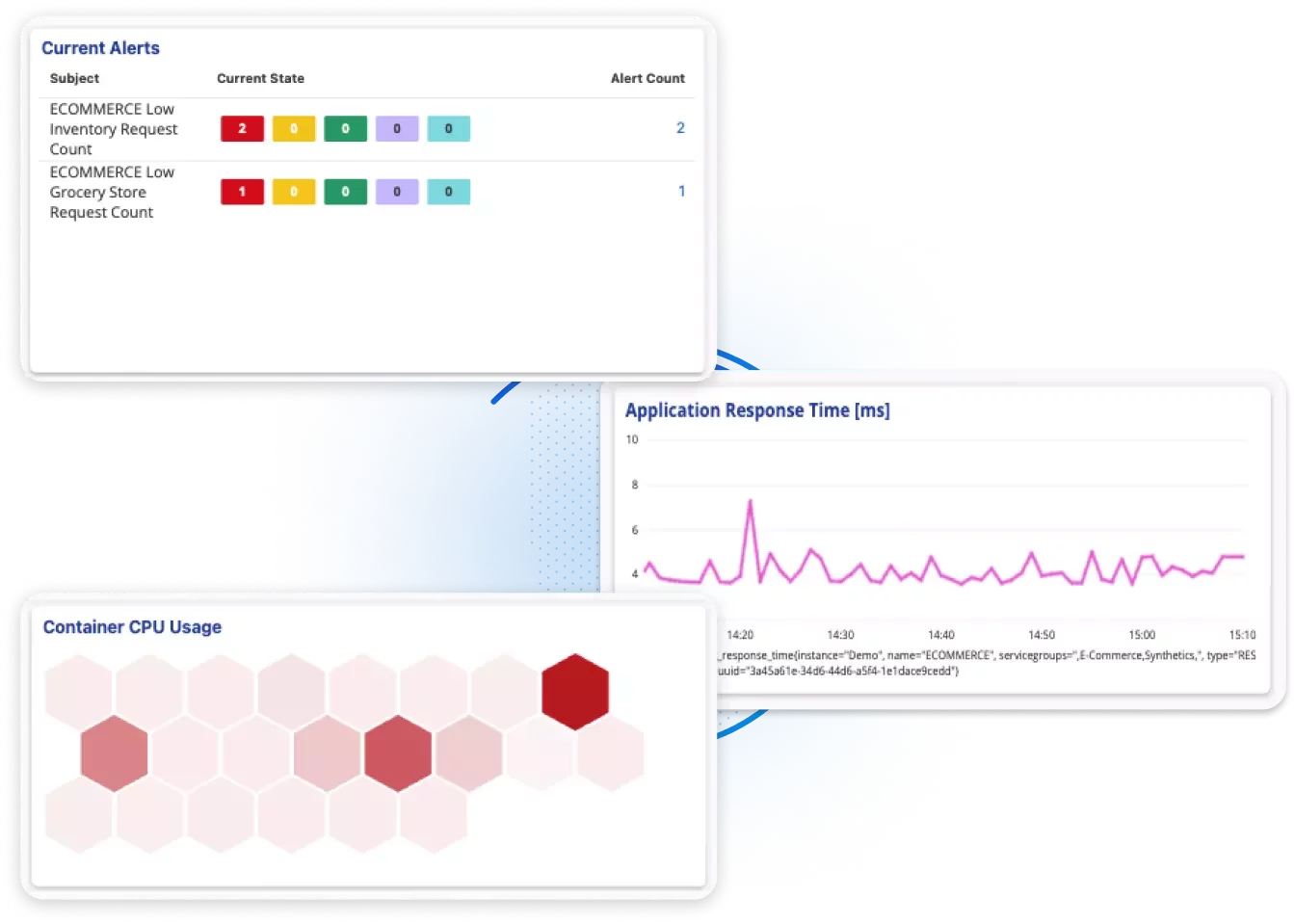
Comprehensive Observability
สภาพแวดล้อมดิจิทัลในปัจจุบันสร้าง Telemetry Data ปริมาณมหาศาลจากทุกมุมของระบบ ไม่ว่าจะเป็น Metrics จากเซิร์ฟเวอร์และเครือข่าย, Tracing จาก Microservices, Logs จาก Cloud และ Containers ไปจนถึงข้อมูลจาก AI Workloads การรวบรวมและวิเคราะห์ข้อมูลเหล่านี้แบบ Real-time คือกุญแจสำคัญในการเข้าใจ Performance ของระบบอย่างแท้จริง
OpsRamp มอบ Observability ที่ครบกว่า ด้วยการรองรับมาตรฐานเปิดอย่าง OpenTelemetry ทำให้สามารถรวบรวม Telemetry Data ครบชุด (MELT) จากทุกแหล่ง และนำเสนอข้อมูลพร้อม Context ที่ชัดเจน ช่วยให้ทีมของคุณมองเห็นปัญหาเชิงลึก วิเคราะห์ได้เร็วขึ้น และตัดสินใจได้อย่างแม่นยำ
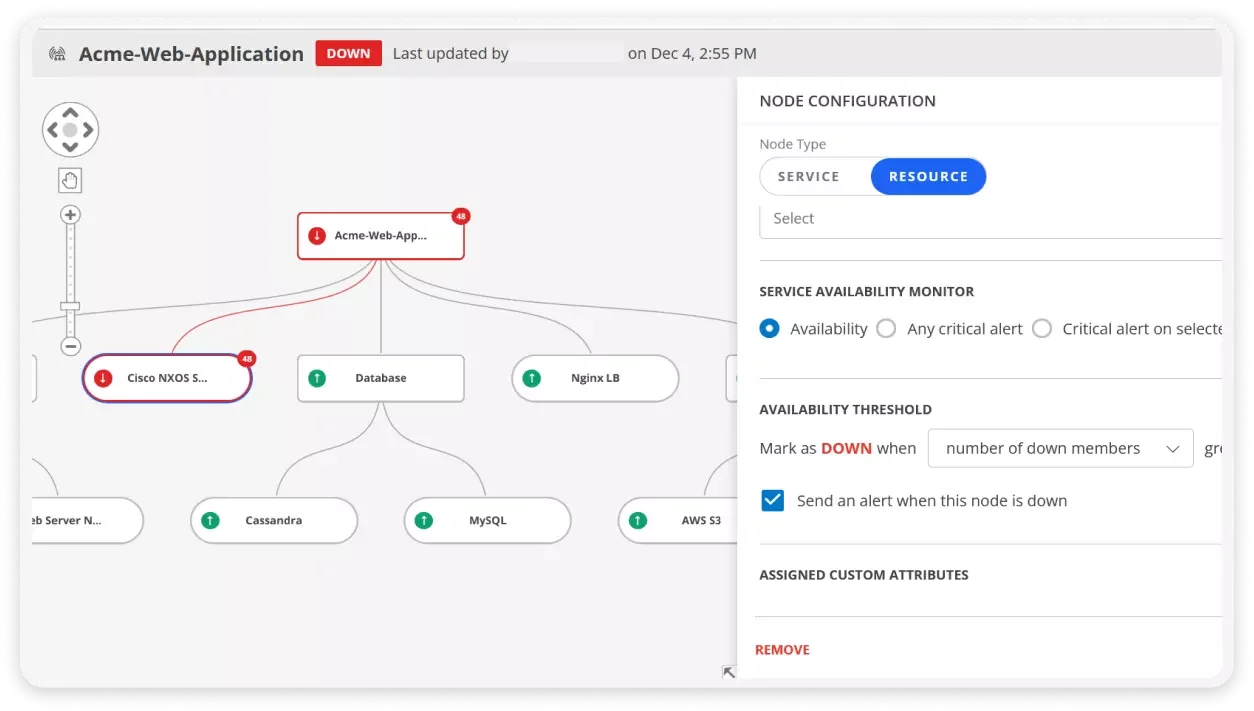
Dynamic Topology
มองเห็นความเชื่อมโยงของระบบแบบไดนามิก เพื่อการวินิจฉัยปัญหาที่แม่นยำกว่า
Business Services ขององค์กรต้องพึ่งพา Servers, Applications และ IT Resources จำนวนมาก ทำให้การระบุปัญหาและเชื่อมโยงเหตุการณ์ไปยังต้นตอที่แท้จริงเป็นเรื่องยาก การทำ Resource Mapping ด้วยมือ การวิเคราะห์ Dependencies และการสร้าง Topology Visualization แบบดั้งเดิมก็ล้วนใช้เวลามากและเสี่ยงต่อความผิดพลาด
OpsRamp แก้ปัญหานี้ด้วย
Dynamic Topology ที่อัปเดตความสัมพันธ์ของระบบแบบเรียลไทม์
Business Service Maps ที่แสดง Dependency พร้อม Context เชิงลึก
การมอนิเตอร์ประสิทธิภาพของ Critical Services และ Infrastructure ที่รองรับอย่างแม่นยำ
คุณจะมองเห็นภาพรวมของบริการและทรัพยากรที่เกี่ยวข้องได้ทันที ช่วยให้วินิจฉัยปัญหาได้เร็วขึ้น ลด Downtime และเพิ่มความมั่นใจในการดำเนินงาน
AI-Powered Analytics

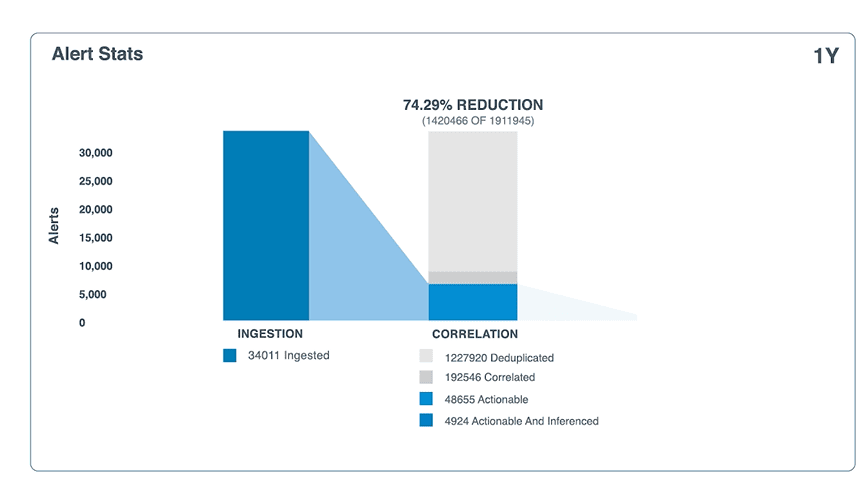
ML-driven Event Correlation
เครื่องมือมอนิเตอร์แบบดั้งเดิมมักสร้าง Alerts จำนวนมาก ทั้งซ้ำซ้อนและเป็น False Positives ทำให้ทีม IT Ops และ DevOps เสียเวลาไปกับข้อมูลที่ไม่จำเป็น และแก้ปัญหาเพียงปลายเหตุ ส่งผลให้ Incident ถูกแก้ล่าช้าและ Downtime ยาวนานขึ้น
OpsRamp ใช้ ML ในการรวม Alerts ที่เกี่ยวข้องให้เป็นเหตุการณ์เดียว พร้อมจัดลำดับตามความรุนแรงและผลกระทบ เพื่อให้ทีมสามารถโฟกัสที่เรื่องสำคัญที่สุดได้ทันที นอกจากนี้ยังสามารถระบุ Root Cause ได้อย่างรวดเร็วด้วยการเชื่อมโยงเหตุการณ์ทั้งต้นทางและปลายทางแบบอัตโนมัติ ช่วยเร่งการวินิจฉัยและลดเวลาแก้ไขปัญหาอย่างมีประสิทธิภาพ
AI-powered Anomaly Detection
มองเห็นความผิดปกติก่อนเกิดปัญหา ยกระดับการมอนิเตอร์จาก Reactive สู่ Proactive
เครื่องมือมอนิเตอร์แบบดั้งเดิมที่ยึดตาม Threshold และกฎแบบตายตัวยากที่จะรับมือกับสภาพแวดล้อม Hybrid ที่ซับซ้อน ซึ่งเต็มไปด้วย Observability Data ปริมาณมหาศาลและเปลี่ยนแปลงรวดเร็ว การตรวจจับรูปแบบหรือความผิดปกติด้วยมือแทบเป็นไปไม่ได้ ทำให้ยากต่อการระบุปัญหาก่อนที่มันจะเกิดขึ้นจริง
OpsRamp ใช้พลังของ AI วิเคราะห์ข้อมูล Observability แบบย้อนหลังเพื่อค้นหาแนวโน้ม รูปแบบ และความผิดปกติที่บ่งบอกถึงการเปลี่ยนแปลงที่ไม่ปกติ ช่วยให้คุณมองเห็นปัญหาที่อาจเกิดขึ้นตั้งแต่เนิ่น ๆ และป้องกันเหตุขัดข้องหรือ Outage ก่อนที่จะส่งผลกระทบต่อประสิทธิภาพของระบบ
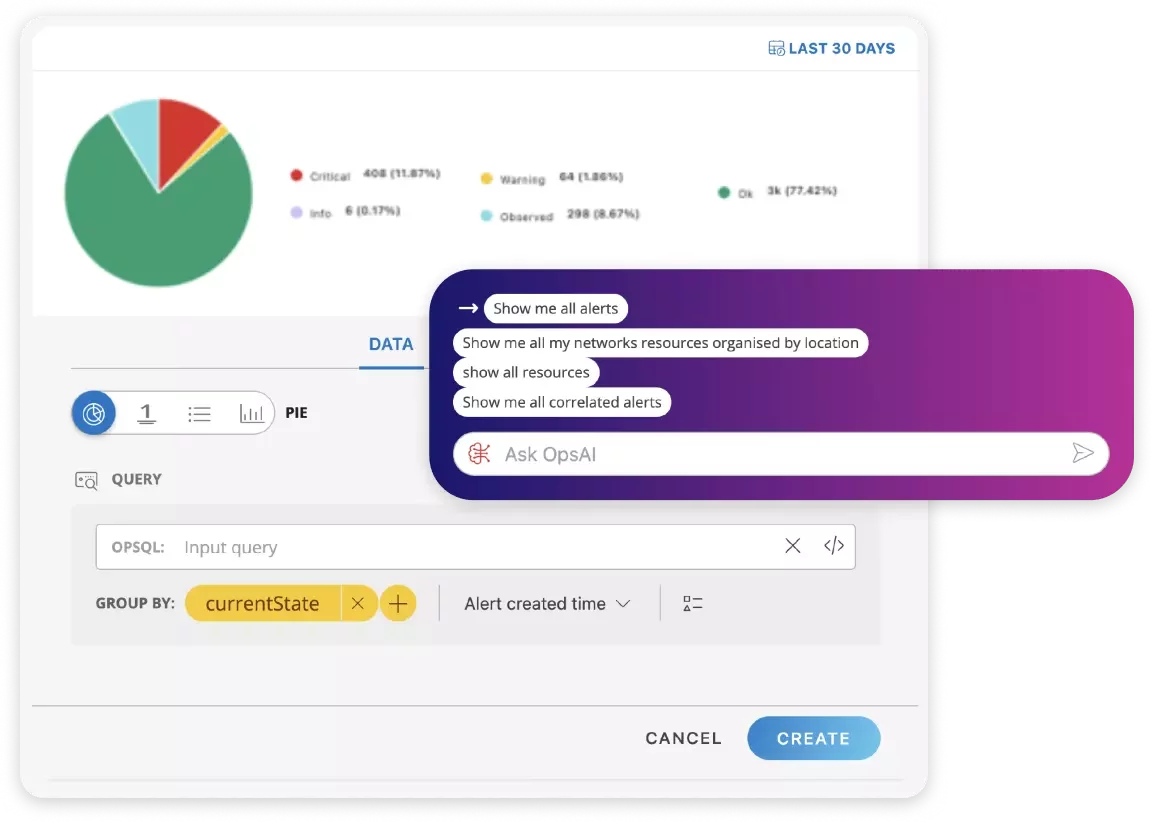
Copilot for IT Operations
OpsRamp’s Operations Copilot ผู้ช่วยอัจฉริยะคนใหม่ของทีมคุณ Copilot ใช้โมเดล AI ที่ออกแบบเฉพาะสำหรับ Observability และสามารถเข้าใจคำถามภาษาธรรมชาติ (Natural Language) เพื่อดึง Insight ที่สำคัญ พร้อมให้คำแนะนำที่เหมาะสมกับบริบทของระบบแบบอัตโนมัติ
ผลลัพธ์คือทีมของคุณสามารถจัดการ Alerts ได้มากขึ้น รองรับ Incidents ได้รวดเร็วขึ้น และบริหาร IT Resources ได้อย่างมีประสิทธิภาพกว่าเดิม—เพิ่ม Bandwidth ให้ทีม พร้อมส่งมอบประสบการณ์ที่ดียิ่งขึ้นให้ทั้งผู้ใช้และลูกค้า
Intelligent Automation

Automated Monitoring Templates
ในสภาพแวดล้อม Hybrid IT ที่ซับซ้อนและกระจายตัว การกำหนด Monitoring Templates ให้ทรัพยากรแต่ละประเภทแบบทำด้วยมือกินเวลามาก สร้างความไม่สอดคล้องกันของมาตรฐาน และเพิ่มโอกาสเกิดข้อผิดพลาด ซึ่งทั้งหมดนี้นำไปสู่ปัญหาด้านการมอนิเตอร์ การมองเห็นระบบ และ incident management ที่ไม่ทันการณ์
OpsRamp แก้ปัญหาเหล่านี้ด้วยการค้นหาทรัพยากร (Auto Discovery) และนำ Monitoring Templates ที่เหมาะสมไปใช้งานแบบอัตโนมัติ ตาม Threshold และมาตรฐานที่คุณตั้งไว้ล่วงหน้า ทำให้ระบบมอนิเตอร์มีความสม่ำเสมอ ลดความผิดพลาด ประหยัดเวลาอย่างมหาศาล และช่วยให้การจัดการ Incident เป็นไปได้ง่ายและรวดเร็วยิ่งขึ้น
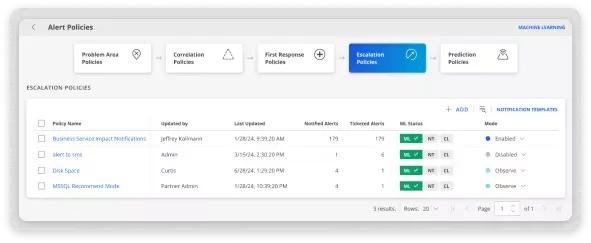
Intelligent Incident Routing
เมื่อเกิด Incident เวลาคือสิ่งสำคัญ แต่ทีมไอทีมักเสียเวลาไปกับการตามหาผู้เชี่ยวชาญและทำขั้นตอนเดิม ๆ ซ้ำซ้อน OpsRamp ใช้ Intelligent Routing เพื่อส่ง Incident ไปยัง SME ที่ถูกต้องทันที พร้อม Runbook Automation ที่จัดการงานแก้ไขอัตโนมัติ ทั้งงานที่เกิดซ้ำและงานที่กำหนดล่วงหน้า ช่วยให้ทีมเริ่มแก้ไขได้เร็ว ลดงาน manual และปิดปัญหาได้ไวกว่าเดิมอย่างมีประสิทธิภาพ
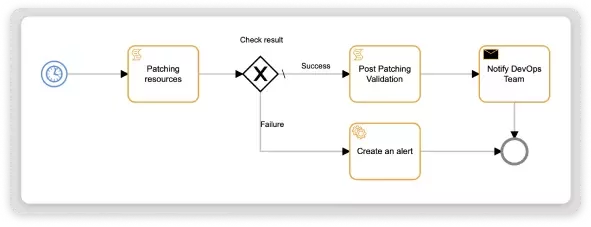
Automated Patching and Configuration
การตั้งค่าที่ล้าสมัยและการจัดการแพตช์ที่ไม่ทั่วถึงในสภาพแวดล้อม Hybrid IT ที่ซับซ้อน นำไปสู่ความเสี่ยงด้านความปลอดภัย ปัญหาด้าน Compliance และประสิทธิภาพบริการที่ลดลง OpsRamp ช่วยแก้ปัญหาเหล่านี้ด้วยการทำ Patch Management, Configuration Management และ Compliance Checks แบบอัตโนมัติ ทำให้สภาพแวดล้อมขององค์กรมีความมั่นคงมากขึ้น ลดช่องโหว่ และรักษามาตรฐานได้อย่างต่อเนื่องโดยไม่ต้องพึ่งงาน manual